
A post on LinkedIn questioned the idea that Schema.org structured data has an impact on what a large language model outputs. Apparently there are some SEOs who are recommending structured data to rank better in AI search engines.
Patrick Stox wrote the following post on LinkedIn:
“Did I miss something? Why do SEOs think schema markup will impact LLM output?”
Patrick said “LLM output” in the context of an SEO recommendation so it’s likely that it’s a reference to ChatGPT Search and other AI search engines. So do AI search engines get their data from structured data?
LLMs are trained on web text, books, government records, legal documents and other text data (as well as other forms of media, too) which is then used to produce summaries and answers but without plagiarizing the training data. What that means is that it’s pointless to think that optimizing your web content will result in the LLM itself sending referrals to that website.
AI search engines are grounded on search indexes (and knowledge graphs) through Retrieval Augmented Generation (RAG). Search engine indexes themselves are created from crawled data, not Schema structured data.
Perplexity AI ranks web-crawled content using a modified version of PageRank on their search index, for example. Google and Bing crawl text data and do things like remove duplicate content, remove stop words, and other manipulation of the text extracted from the HTML, plus not every page has structured data on it.
In fact, Google only uses a fraction of the available Schema.org structured data for specific kinds of search experiences and rich results, which in turn limits the kind of structured data that publishers use.
Then there’s the fact that both Bing and Google’s crawlers render the HTML, identify the headers, footers and main content (from which they extract the text for ranking purposes). Why would they do that if they’re going to rely on Schema structured data, right?
The idea that it’s good to use Schema.org structured data to rank better in an AI search engine is not based on facts, it’s just fanciful speculation. Or it could be from a “game of telephone” effect where one person says something and then twenty people later it’s transformed into something completely different.
For example, Jono Alderson proposed that structured data could be a standard that AI search engines could use to understand the web better. He wasn’t saying that AI search engines currently use it, he was just proposing that AI search engines should consider adopting it and maybe that post got telephoned into a full-blown theory twenty SEOs later.
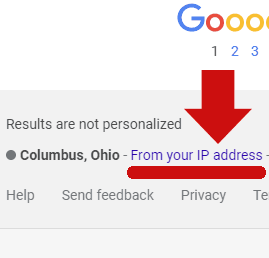
Unfortunately, there’s a lot of unfounded ideas floating around in SEO circles. The other day I saw an SEO assert in social media that Google Local Search doesn’t use IP addresses in response to search “near me” search queries. All anyone had to do to test that idea is to sign into a VPN, choose a geographic location for their IP address and do a “near me” search query and they will see that the IP address used by the VPN influenced the “near me” search results.
Screenshot Of Near Me Query Influenced By IP Address
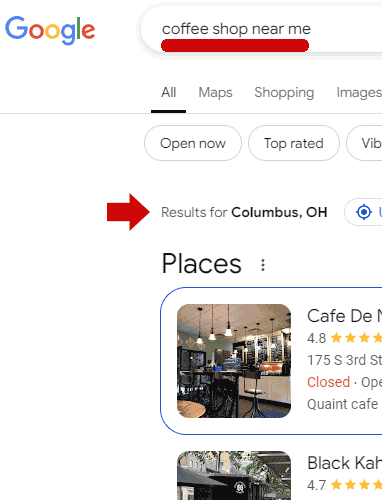
Google even publishes a support page that says they use IP address to personalize search results yet there are people who believe otherwise because some SEO did a correlation study and when questioned we’re back to someone bellowing that Google lies.
Will You Believe Your Lying Eyes?
Schema.Org Structured Data And AI Search Results
“SEOs” recommending that publishers use Schema.org structured data for LLM training data also makes no sense because training data isn’t cited in LLM output, just for output that is sourced from the web, which itself is sourced from a search index that’s from a crawler. As mentioned earlier, publishers only use a fraction of available Schema.org structured data because Google itself only uses a tiny fraction of it. So it makes no sense for an AI search engine to rely on structured data for their output.
Search marketing expert Christopher Shin (LinkedIn profile) commented:
“Thinking the same thing after reading your post Patrick. This is how I interpret it currently. I thought LLM’s typically do not generate responses from search engines serps but rather from data interpretation. Right? But schema data markup would be used by SER{s to show rich snippets etc. no? I think the key nuance with schema and LLMs is that search engines use schema for SERPs whereas LLM’s use data interpretation when it comes to how schema impacts LLM’s.”
People like Christopher Shin and Patrick Stox give me hope that pragmatic and sensible SEO is still fighting to get through the noise, Patrick’s LinkedIn post is proof of that.
Pragmatic SEO
The definition of pragmatic is doing things for sensible and realistic reasons and not on opinions that are based on incomplete information and conjecture.
Speaking as someone who’s been involved with SEO since virtually the birth of it, not thinking things through is why SEOs and publishers have traditionally wasted time with vaguely defined issues, spun their wheels on useless activities like superficial signals of EEAT and so on and so forth. It’s truly dispiriting to point to documentation and official statements and get blown back with statements like, “Google lies.” That kind of attitude makes a person “want to holler.”
A little more pragmatic SEO please.


















 English (US) ·
English (US) ·